May 10, 2026
Table of Contents
The 80% code coverage bar has been the industry’s comfort blanket for over a decade. Teams set it as a CI gate, PRs get blocked if they dip below it, and everyone sleeps a little better knowing the number is green. The logic was reasonable: writing thorough tests takes effort, 80% captures the important paths, and the remaining 20% delivers diminishing returns.
Then AI coding agents arrived and rewrote the economics. Cursor, Claude Code, Codex - these tools generate test suites that hit 90%, 95%, even 100% coverage in minutes. The old ROI argument evaporated overnight. If reaching 100% is effortless, why not mandate it? So teams do. CI goes green. Coverage reports glow. Everyone feels confident. But a 2025 study on mutation-guided test generation found something unsettling: some test suites achieved 100% code coverage with only a 4% mutation score - meaning 96% of potential bugs survived undetected behind that perfect coverage number. That perfect green number masked a test suite with almost zero real fault-detection capability.

What Does 100% Coverage Actually Measure?
Coverage answers exactly one question: did this line execute during the test run? It never asks whether the test verified the result. It cannot tell whether the assertion was meaningful. It does not know if the test checked the right thing. Google’s engineering infrastructure - processing over four billion test executions daily across two billion lines of code - explicitly rejects universal coverage targets in favour of “useful coverage”: tests that detect real defects.
| What Coverage Measures | What Coverage Misses |
|---|---|
| This line of code executed | Whether the test actually verified the output |
| All branches were taken at least once | Whether boundary conditions were tested |
| The function was called | Whether the function returned the correct result |
| No lines were skipped | Whether changing the logic would break any test |
A 2026 causal inference study on JavaScript and TypeScript projects went further, using causal methodology to show that the relationship between coverage and bug prevention is weaker than most teams assume once you control for confounding factors like code complexity and developer experience.
A 2026 analysis of test coverage vs code coverage puts it bluntly: teams routinely ship bugs with 95%+ code coverage while believing releases are “safe”, because they confuse lines executed with features validated. So if coverage measures execution and not correctness, how does a bug survive 100% coverage?
How Can a Bug Survive 100% Coverage?
Consider a simplified demo that illustrates how these boundary bugs can happen in practice. A function determines which service tier a customer qualifies for based on age. Business rules: anyone under 18 is a minor (cannot open accounts under Singapore’s Banking Act), anyone 60 or above is a senior (entitled to special interest rates).
func CustomerTier(age int) string {
if age < 0 {
return "invalid"
}
if age < 17 { // BUG: should be < 18
return "minor"
}
if age > 60 { // BUG: should be >= 60
return "senior"
}
return "adult"
}
The test suite uses table-driven tests with explicit assertions on every return value:
var customerTierCases = []struct {
name string
age int
want string
}{
{"When age is -1, should return invalid", -1, "invalid"},
{"When age is 10, should return minor", 10, "minor"},
{"When age is 30, should return adult", 30, "adult"},
{"When age is 70, should return senior", 70, "senior"},
}
Run it. 100% statement coverage. All 4 tests pass. Every branch is exercised. Every return value is asserted. CI is green.
But two bugs are hiding in plain sight:
| Test Case | Input | Bug Present? | Result |
|---|---|---|---|
| age = 10, expect “minor” | 10 < 17 = true | Same as 10 < 18 | PASS |
| age = 30, expect “adult” | 30 < 17 = false | Same as 30 < 18 | PASS |
| age = 70, expect “senior” | 70 > 60 = true | Same as 70 >= 60 | PASS |
Every test passes because the inputs are far from the boundary. Ages 10, 30, and 70 produce identical results whether the threshold is 17 or 18, whether the comparison is > or >=. The tests never ask: “What happens to someone who is exactly 17?” or “What happens to someone who is exactly 60?”
Two weeks after deployment: a 17-year-old opens a credit card account online - a regulatory compliance violation under Singapore’s Banking Act. A 60-year-old retiree is denied her entitled senior interest rate. Both bugs survived 100% coverage because coverage measures whether the line ran, not whether the test would break if the line changed.
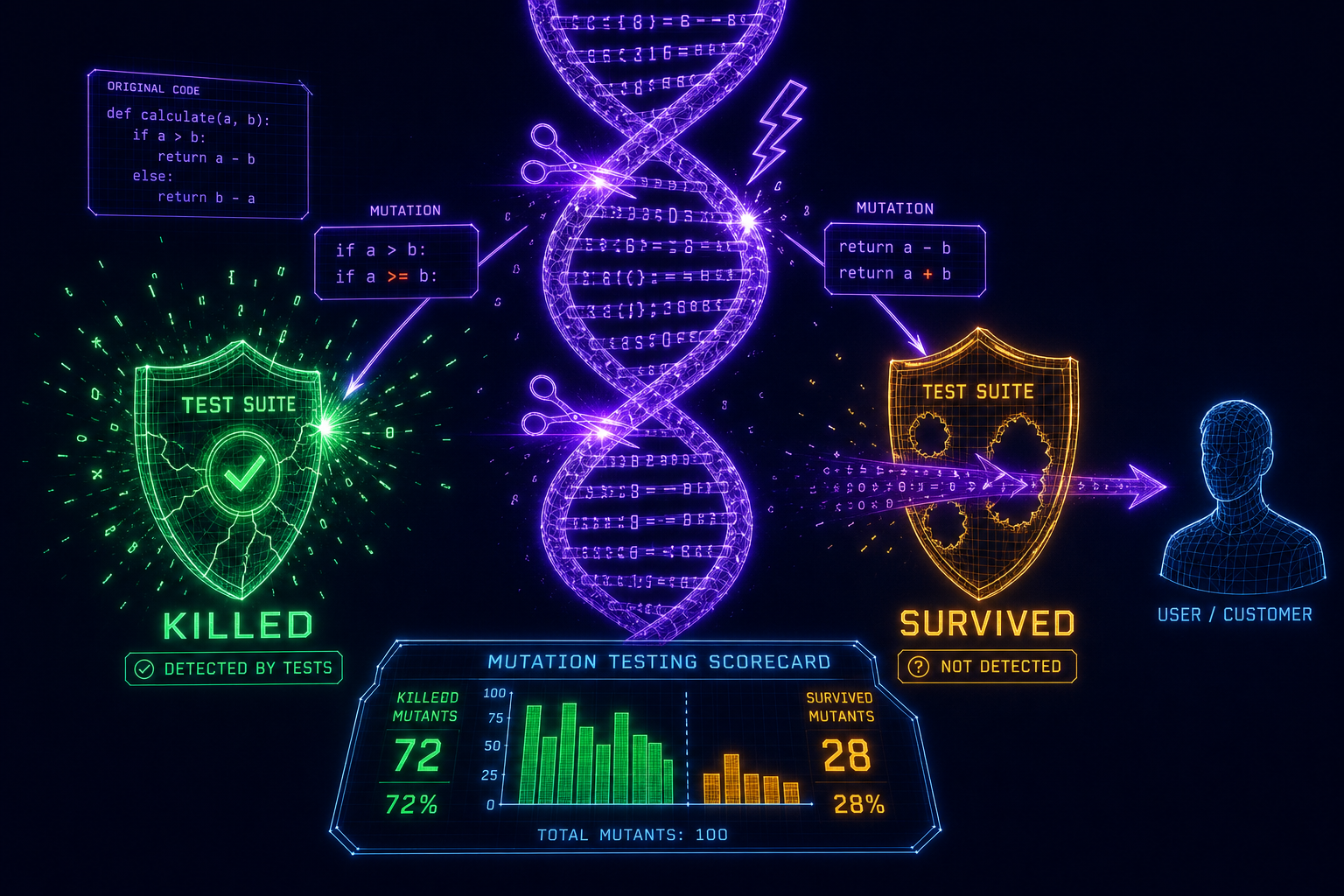
What Actually Catches These Bugs?
Mutation testing. The concept is deceptively simple: make small changes to your code (mutations) and check if your tests fail. If a test fails, the mutation is “killed” - your test caught it. If all tests still pass despite the change, the mutation “survived” - your test suite has a blind spot.
flowchart TD
A["1/ Original Code"] --> B["2/ Mutate: Change < 17 to < 18"]
B --> C{"3/ Run Tests"}
C -->|Tests still pass| D["SURVIVED - Blind spot!"]
C -->|Tests fail| E["KILLED - Tests caught it"]
A --> F["2/ Mutate: Change > 60 to >= 60"]
F --> G{"3/ Run Tests"}
G -->|Tests still pass| H["SURVIVED - Blind spot!"]
G -->|Tests fail| I["KILLED - Tests caught it"]
For the banking function, a mutation testing tool would generate mutants like:
| Mutation | What Changes | Tests Detect It? |
|---|---|---|
age < 17 becomes age < 18 | Fixes the bug (correct threshold) | No - all tests still pass |
age < 17 becomes age < 16 | Shifts boundary further wrong | No - age=10 still satisfies 10 < 16 |
age > 60 becomes age >= 60 | Fixes the bug (correct comparison) | No - all tests still pass |
"minor" becomes "adult" | Returns wrong tier for minors | Yes - age=10 test fails |
The first three mutations survive - they expose exactly the boundary blind spots that coverage cannot see. A 2025 analysis of AI-generated tests found that only 38% of injected mutations were caught, meaning over 60% of potential bugs went undetected despite high coverage numbers. The mutation score - the percentage of mutations killed - is a far more honest measure of test effectiveness and boundary testing quality than coverage alone.
Why Does This Matter More in the Age of AI Coding?
AI coding agents have fundamentally changed the economics of testing. When Cursor, Claude Code, and Codex can generate test suites that hit 100% coverage in minutes, the 80% coverage bar becomes meaningless - not because it is too low, but because reaching it (or exceeding it) no longer signals quality.
The pattern is predictable - and it mirrors the broader vibe coding problem at a testing level. An AI agent generates a function, then generates tests for that function, then reports 100% coverage. The developer sees green and moves on. But the AI optimises for what it can measure - line execution - not for what matters - fault detection. It generates tests with values far from boundaries because those are the simplest to reason about. The result is a test suite that executes every line while verifying almost nothing about correctness.
This is where mutation testing becomes essential. It asks the question coverage cannot: “Would any test fail if we changed this code?” In a team where AI agents generate both production code and tests, mutation testing is the most effective tool to ensure that the tests actually cover the behavior they claim to cover.
| Quality Gate | What It Catches | AI Agent Blind Spot |
|---|---|---|
| Linting | Style violations, static errors | None - AI agents lint well |
| Code Coverage | Untested code paths | AI easily achieves 100% with weak tests |
| Mutation Testing | Ineffective tests, boundary gaps | Forces tests to verify behavior, not just execute lines |
The CI pipeline for AI-generated code should treat mutation testing the same way we treat linting: a non-negotiable gate that blocks merge when the score drops. Coverage tells you what is untested. Mutation testing tells you what is poorly tested. Both together give you an honest picture of whether your test suite would catch a real bug before your users do - the same principle behind testing what users actually experience, not just what the code executes.
Key Takeaways
| Metric | What It Tells You | What It Misses |
|---|---|---|
| Code Coverage | Which lines of code executed during tests | Whether the tests verify correct behavior |
| Mutation Score | How many code changes your tests can detect | Nothing - it is the ground truth for test quality |
The 80% coverage bar served its purpose when writing tests was expensive. AI coding agents eliminated that cost barrier. But they also made it trivially easy to generate tests that hit every line while checking nothing meaningful. The answer is not more coverage - it is effective coverage, measured by whether your tests would break if the code changed.
One thing you can do today: pick one critical function in your codebase - a pricing calculation, an access control check, a compliance rule. Ask yourself: “If I changed the < to <= in this condition, would any test fail?” If the answer is no, you have found your first mutation testing candidate.
The full Go demo is available on GitHub Gist - 100% coverage, two surviving bugs, ready to run with any mutation testing tool of your choice.
Share :
You May Also Like

The Hard Truth About OpenClaw
Every few months, a new open-source AI framework captures the collective imagination of the tech community. Right now, that spotlight belongs to OpenClaw. Forums light up with screenshots, YouTube …
Read More
Less Is More - How My Tech Stack Got Leaner and Meaner
I had a Kubernetes cluster running inside my NAS. ArgoCD managing deployments. Cloudflare Zero Trust handling ingress. On paper, it was an enterprise-grade homelab. In practice, it was an …
Read More