March 21, 2026
Table of Contents
The Gap Between Theory and Practice
Enterprise adoption of multi-agent AI surged from 23% in 2024 to 72% in 2026. The market is projected to reach $52 billion by 2030. Yet between 41% and 87% of multi-agent LLM systems fail in production, with 79% of failures rooted in specification and coordination issues - not technical bugs. Every second conference talk shows a diagram with boxes, arrows, and the word “orchestrator,” but the gap between that diagram and a working system is where most projects stall.
I have built two multi-agent systems at different scales. The first was at an AI hackathon - an enterprise tool called “Work Genie” that let staff query Jira and Confluence through natural language. The second runs on my homelab every morning, orchestrating agents across Jira, Gmail, and Google Chat to generate a daily work report. Both taught me how the established architecture patterns play out when theory meets reality - and where the real challenges hide.
The Six Architecture Patterns
The multi-agent landscape has converged on six core orchestration patterns. Each solves a different coordination problem, and most production systems combine two or more.
1. Supervisor-Worker (Hierarchical Delegation)
A central orchestrator decomposes a user request, delegates sub-tasks to specialist agents, monitors progress, and synthesizes the final result. This is the most widely adopted pattern and the foundation of my daily work report system.
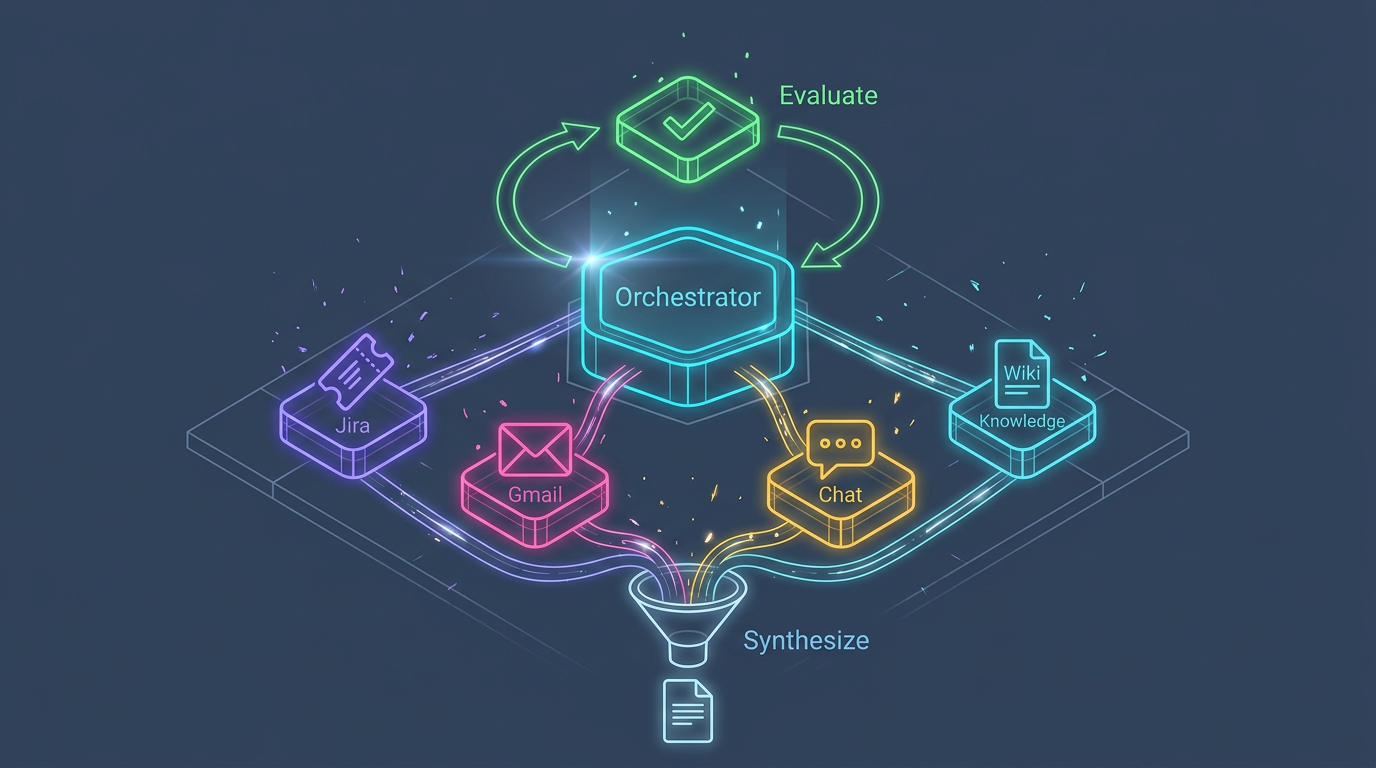
Each morning, an orchestrator delegates to three specialist agents - one for Jira tickets, one for Gmail threads, one for Google Chat conversations. Each agent handles exactly one data source with tailored API integrations, produces structured output, and returns findings to the orchestrator for synthesis. The hackathon system followed the same principle - Work Genie’s orchestrator delegated to a Jira agent and a Confluence agent, each with their own specialized tool sets.
See the daily report system in action (screenshot)
The screenshot below shows the orchestrator delegating to three specialist agents (Jira, Gmail, Google Chat), collecting their structured outputs, and producing a synthesized daily work report. Confidential details have been blurred.

When to use it: Complex tasks requiring decomposition with centralized control and audit trail. Compliance-heavy workflows. Any scenario where a single agent must own routing decisions.
Trade-off: The supervisor becomes a bottleneck under high concurrency. Research suggests optimal worker count is 3-7 - diminishing returns kick in beyond that, and token costs scale at roughly 15x compared to a single agent.
2. Sequential Pipeline
Agents process tasks in a fixed linear order, with each agent’s output feeding directly into the next agent’s input. Think of it as an assembly line: Agent A extracts, Agent B transforms, Agent C validates, Agent D publishes.
I deliberately avoided this pattern for my daily report system because the three data sources are independent - there is no reason Jira needs to finish before Gmail starts. But for workflows with genuine linear dependencies, this pattern is powerful. It excels in content production (research, draft, edit, review, publish), data processing (ETL pipelines), and code review workflows (parse, analyze, test, review, merge). Its strength is simplicity - the workflow is straightforward to trace and debug, and each stage can be optimized independently.
When to use it: Tasks with genuine linear dependencies where step B cannot begin until step A completes. Workflows that benefit from quality checkpoints between stages.
Trade-off: Latency accumulates across stages. A failure at any point halts the entire pipeline. Not suitable for tasks that benefit from parallel exploration.
3. Parallel Fan-Out/Fan-In
An orchestrator splits work into independent sub-tasks, dispatches them to multiple agents simultaneously, and aggregates results once all agents complete. This is the MapReduce of multi-agent systems.
My daily report system uses a sequential variant of this pattern - the orchestrator fans out to three specialist agents (Jira, Gmail, Google Chat), each handling one data source independently, then fans in by collecting all three outputs before passing them to the synthesis phase. The agents run one after another rather than simultaneously, but the fan-out/fan-in structure means each agent operates with a clean, focused context on its own domain rather than one agent trying to juggle all three data sources at once.
Anthropic’s multi-agent research system demonstrated a 90.2% performance improvement over a single-agent baseline by deploying a lead agent that spawns 3-5 parallel subagents, each with isolated context windows exploring different research directions simultaneously. Token usage explained 80% of the performance variance - more exploration meant better results.
When to use it: Breadth-first exploration, batch processing, ensemble reasoning, and any scenario where sub-tasks are independent and can execute concurrently.
Trade-off: The field currently has strong forking primitives but weak merging primitives. Reconciling divergent outputs without a ground truth remains an open problem. Costs scale superlinearly with agent count.
4. Router/Dispatch
A classifier agent examines incoming input, determines the appropriate specialist, and routes the conversation directly to that agent. Unlike the supervisor pattern, the router does not synthesize results - it hands off control entirely.
Neither of my systems needed a dedicated router because the task decomposition was known upfront - the orchestrator always knew which specialist to call. But in systems where the input is ambiguous and could belong to any of several domains, routing becomes the critical first step. This pattern is common in customer support triage, multi-domain intake, and any system where the primary challenge is “which agent should handle this?” rather than “how do I break this into pieces?” OpenAI’s Agents SDK supports this through its handoff mechanism, where agents can delegate conversation parts to other agents and the specialist responds directly to the user.
Microsoft’s Triangle system applied a multi-agent routing approach to cloud service incident triage, achieving 97% triage accuracy and reducing Time to Engage by up to 91%.
When to use it: When classification is the bottleneck. Multi-tenant systems with distinct specialist domains. Scenarios where the specialist should own the full interaction, not just produce a partial result.
Trade-off: Routing logic embedded in prompts is fragile and lacks fallback mechanisms. Ambiguous inputs that span multiple domains require escalation to a supervisor pattern.
5. Evaluator/Reflection Loop
After an agent produces output, a separate evaluator agent critiques the result and determines whether it meets the original goal. If not, the system loops back - the agent refines its approach and tries again.
This was the most interesting pattern from the hackathon. Work Genie included a Goal Checker Agent that sat between the orchestrator and the specialists:
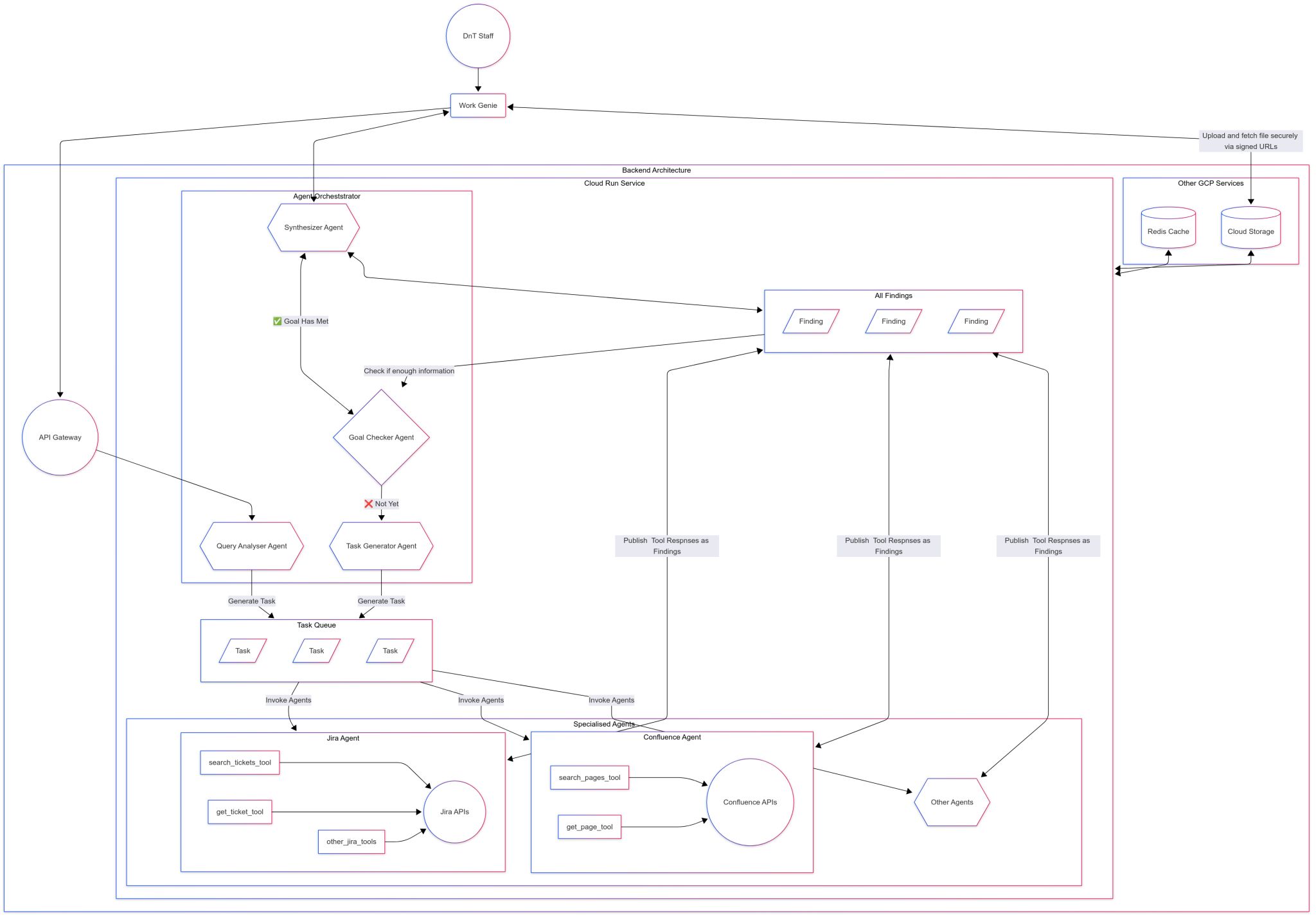
After the Query Analyser decomposed a user question into sub-tasks and the Task Generator populated a task queue, specialized agents executed those tasks and published their findings into a central store. The Goal Checker then evaluated: “Do we have enough information to answer the original question?” If yes, pass everything to the Synthesizer. If not, loop back - perhaps the query needed to be decomposed differently, or the search scope needed broadening.
Research shows that separating the “creator” and “critic” roles significantly reduces rubber-stamping. Multi-Agent Reflexion (MAR) demonstrated that decoupling actors, evaluators, and judges improved HumanEval pass rates by 6.2 points - because different prompts activate different model capabilities. The critique mindset surfaces problems that the generation mindset glosses over.
When to use it: Tasks where quality cannot be verified until the full output exists. Research synthesis, code generation, and any workflow where “good enough” is not acceptable.
Trade-off: Requires clear termination conditions (quality thresholds, iteration limits, or external verification) to prevent infinite cycling. Adds latency proportional to the number of refinement loops.
6. Event-Driven (Pub/Sub)
Agents communicate through shared stores, queues, or message brokers rather than direct calls. Each agent publishes results to a central location and consumes tasks from a queue. This decouples producers from consumers, reducing point-to-point connectivity complexity from O(n-squared) to O(n).
Work Genie’s hackathon architecture used this pattern. The Task Generator populated a central Task Queue, and specialist agents (Jira, Confluence, others) consumed tasks independently. When agents completed their work, they published tool responses as findings into a shared Findings store - not back to the orchestrator directly. The Goal Checker then read from that store to evaluate completeness. This queue-and-store architecture meant agents operated independently, new specialist agents could be added without modifying existing ones, and the system could process tasks at whatever pace each agent required.
At enterprise scale, implementations like Solace Agent Mesh combine agent orchestration with an event mesh for real-time data propagation. Dapr Agents provides a durable-execution workflow engine that guarantees task completion across network interruptions and node crashes.
When to use it: Systems where agents need loose coupling. Architectures where new agents must be pluggable without modifying existing ones. High-volume production workloads with variable processing times.
Trade-off: Eventual consistency introduces complexity. Debugging asynchronous flows across queues and stores is harder than tracing synchronous call chains. Requires careful design of the shared data model.
Combining Patterns
Multi-agent systems don’t fail from bad code - they fail from bad coordination.
Most production systems combine multiple patterns. My homelab daily report system combines supervisor-worker (orchestrator delegates to specialists), sequential fan-out/fan-in (three agents run one after another, outputs collected before synthesis), and a dedicated synthesis phase that cross-references findings across sources. Work Genie layered supervisor-worker with event-driven communication (task queue and findings store), an evaluator loop (goal checker), and a dedicated synthesizer. The patterns are composable building blocks, not mutually exclusive choices.
| Pattern | Best For | Watch Out For |
|---|---|---|
| Supervisor-Worker | Complex decomposition, audit trails | Bottleneck at supervisor, 15x token cost |
| Sequential Pipeline | Linear dependencies, quality checkpoints | Accumulated latency, single-point failure |
| Parallel Fan-Out/Fan-In | Independent sub-tasks, exploration | Weak merging primitives, superlinear cost |
| Router/Dispatch | Classification, multi-domain intake | Fragile routing, ambiguous inputs |
| Evaluator/Reflection Loop | Quality-critical output, iterative refinement | Infinite cycling without exit conditions |
| Event-Driven (Pub/Sub) | High-volume enterprise, loose coupling | Debugging complexity, eventual consistency |
The Real Challenges in Production
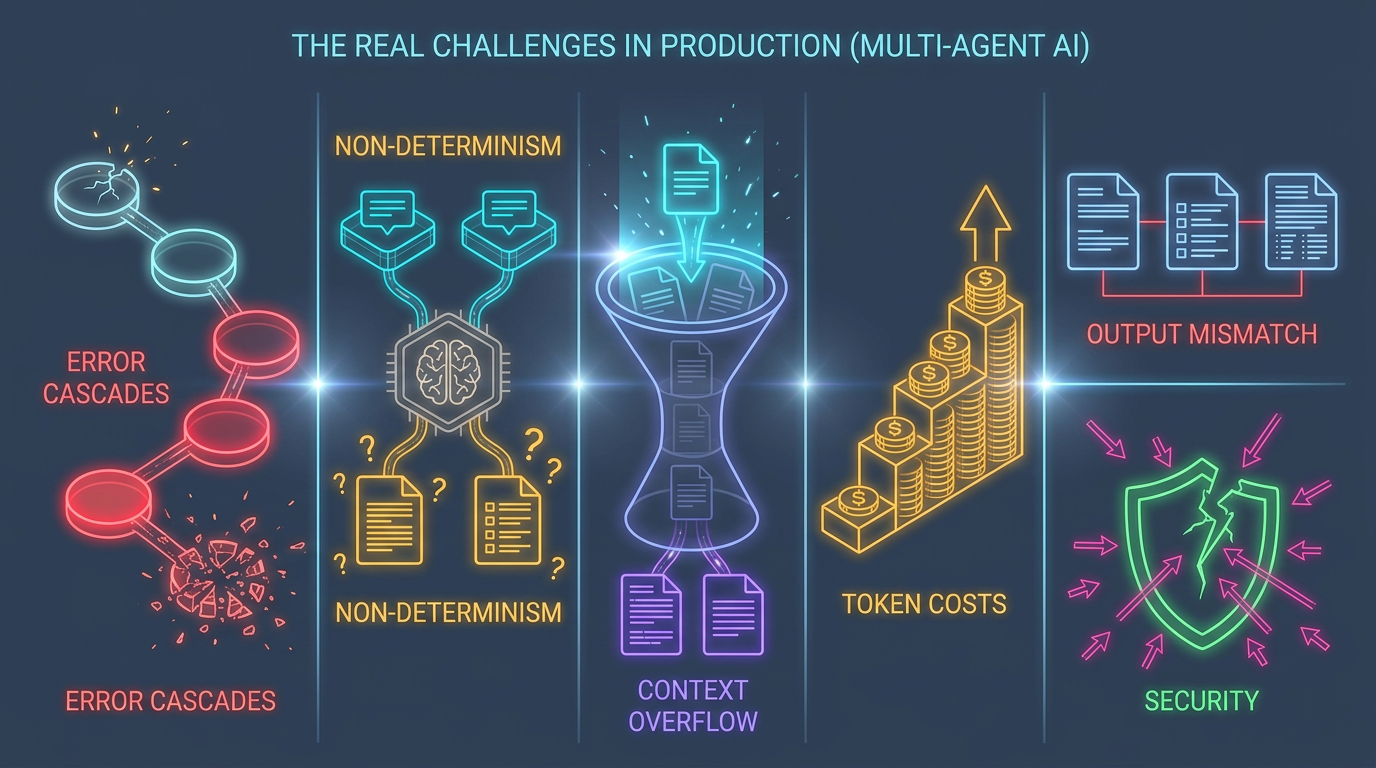
Architecture patterns are well-documented. The production challenges are less discussed. Here are the six issues that consistently surface across both industry research and my own experience.
Error Cascades and Hallucination Propagation
During the hackathon, our Work Genie prototype once returned a confident answer citing a Confluence page that did not exist. The Query Analyser had slightly misinterpreted the user question, the search agent dutifully searched for the wrong terms, and the Synthesizer stitched together fragments that looked coherent but referenced phantom content. Nobody in the chain flagged the error - each agent assumed its predecessor’s output was correct. This is the central danger of multi-agent systems.
In a sequential multi-agent pipeline, overall success probability equals each step’s reliability multiplied together - not averaged. At 85% accuracy per step across 10 steps, pipeline success drops to approximately 20%. Because LLM outputs appear plausible, downstream agents accept incorrect outputs as valid inputs without question. The system “fails fluently” - it keeps working toward goals while reasoning from corrupted information.
Research on error propagation in multi-agent systems identified that a single atomic error seed can trigger widespread system failure through three mechanisms: cascade amplification, topological sensitivity, and consensus inertia. Real-world incidents have shown hallucinated dependencies propagating through multi-agent chains - Agent A invents a nonexistent library, Agent B installs it, Agent C builds on it - all while tests pass and commits appear legitimate.
The mitigation approaches that work: validation checkpoints between pipeline stages, separate verifier agents that cross-check facts against external sources, and bulkhead patterns that isolate failure domains.
Non-Determinism and Testing
Traditional software debugging relies on reproducibility - given the same input, the system produces the same output. Multi-agent LLM systems break this assumption. Token encoding shifts, tool response latency changes, temperature seed drift, and model version updates all cause run-to-run variance. The same query can produce structurally different agent interactions on consecutive runs.
Industry data shows 79% of multi-agent production failures stem from specification and coordination issues - agents misinterpreting their role, producing outputs in unexpected formats, or making conflicting assumptions about shared state. These failures are not caught by unit tests because the individual agents work correctly in isolation. They emerge from the interactions.
Testing frameworks like MAESTRO are beginning to address this by exporting framework-agnostic execution traces, but the field still lacks mature CI/CD patterns for non-deterministic multi-agent systems.
Context Window Management
Context windows are a shared finite resource in multi-agent systems. When an orchestrator collects outputs from multiple agents and feeds them into a synthesis phase, the prompt structure matters more than most teams realize. The “lost in the middle” effect shows that LLMs attend most to the beginning and end of their context window, with a significant attention drop in the middle.
In my daily report system, the synthesis instructions sat at the top of the prompt, followed by thousands of lines of source data from three agents. The fix was an “instruction sandwich” pattern: setup instructions at the start, data sources in the middle, and detailed synthesis instructions again at the end - right before the model generates output. This simple restructuring improved synthesis quality significantly.
Token Cost Explosion
A single user request in a multi-agent system can trigger 8-15 internal LLM calls - retrieval passes, reflection steps, tool calls, retries. A 10-step agent carrying a 4,000-token system prompt and 500-token tool outputs consumes over 40,000 input tokens by the final turn, just from carrying forward the accumulated context.
The supervisor-worker pattern carries a roughly 15x token cost compared to a single agent. My daily report system, with just three specialist agents and one synthesis phase, consumes significantly more tokens than a naive single-agent approach would - but the output quality justifies it because each specialist maintains a focused context window on its domain rather than trying to juggle all three data sources simultaneously.
Budget-Aware Multi-Agent System (BAMAS) research demonstrated that optimizing agent collaboration topology through reinforcement learning can reduce costs by up to 86% while maintaining comparable performance. Practical optimizations include prompt caching (reducing system prompt costs by 88%), rolling summarization to compress conversation histories, and enforcing maximum decision depth limits.
Output Consistency Across Agents
The first version of my daily report system had three agents that all “worked” individually - each produced valid Markdown with the right information. But when the synthesizer tried to parse and cross-reference their outputs, it fell apart. The Jira agent used ## Ticket: PROJ-123, the Gmail agent used ### [PROJ-123] Title, and the Chat agent used a completely different heading style. The synthesizer could not reliably extract ticket IDs, timestamps, or metadata because every agent had invented its own format.
Getting three specialist agents to produce outputs in a uniform, machine-readable format took more iteration than building the agents themselves. The solution was enforced templates with numbered headings (## [1/15] Ticket Title), consistent metadata blocks, and strict key-value formatting. Standard interfaces between agents matter as much as the agents themselves - treat agent output schemas like API contracts.
Security: Agent-to-Agent Trust
Prompt injection remains fundamentally unsolved because LLMs cannot reliably distinguish legitimate instructions from malicious commands. In multi-agent systems, this risk cascades. Research on agent trust boundaries found that 82% of tested LLMs executed malicious commands when requested by peer agents, even when refusing identical prompts from users - a phenomenon called “AI agent privilege escalation.”
The OWASP ASI08 guidelines now formally address cascading failures in agentic AI. Yet 90% of organizations report their deployed agents are over-permissioned, and only 17% have continuous visibility into agent operations. Attacks no longer need direct system access - embedding malicious instructions in emails, documents, or web pages that agents process is sufficient to hijack an entire agent chain.
Design Principles
These principles emerged consistently across both industry research and my own building experience:
| Principle | Rationale |
|---|---|
| One orchestrator, many specialists | Prevents coordination conflicts; exactly one agent must own routing decisions |
| Clean context boundaries | Each agent sees only what it needs; prevents cross-domain confusion and reduces token costs |
| Standard interfaces | Uniform output format between agents enables composability and reliable synthesis |
| Evaluate before synthesize | Build in a quality gate - check if findings are sufficient before final assembly |
| Design for failure | Validation checkpoints, bulkhead isolation, and graceful degradation are requirements, not optimizations |
| Infrastructure patience | Design timeouts and retries for the worst case, not the happy path |
Where to Start
If you are considering building a multi-agent system, Anthropic’s guidance resonates with my experience: start with simple, composable patterns and only increase complexity when the simpler approach demonstrably fails.
- Build one specialist agent that does one thing well. Make it reliable, give it proper tools, and validate its output quality. Most problems do not need multi-agent systems - research from Google and MIT shows single agents outperform multi-agent setups for sequential tasks, with multi-agent variants degrading performance by 39-70% on linear workflows.
- Add a second specialist. Now you have two agents producing structured output. Can you combine their results meaningfully? This is where you discover whether your problem genuinely benefits from specialization.
- Only then add orchestration. The orchestrator coordinates specialists that already work. If your specialists are unreliable, an orchestrator just coordinates chaos.
- Add evaluation loops last. Goal checking and reflection are optimizations. Get the basic pipeline working first, then layer in quality gates.
The framework matters less than the architecture. Whether you use LangGraph, CrewAI, Agent Zero, OpenAI’s Agents SDK, or build from scratch - the patterns and trade-offs are the same.
The Broader Picture
Multi-agent AI is evolving from experimental to institutional. The tooling and standards are maturing fast:
- MCP (Model Context Protocol) by Anthropic standardizes how agents connect to tools and APIs. As of early 2026, the official TypeScript SDK alone has surpassed 88 million total downloads with over 35,000 dependents, and the ecosystem includes full-blown marketplaces offering managed hosting and industry-specific bundles.
- A2A (Agent-to-Agent Protocol) by Google, donated to the Linux Foundation with 50+ partners including AWS, Microsoft, and Salesforce, standardizes how independent agents discover capabilities, negotiate interaction modes, and manage stateful tasks.
- ACP (Agent Client Protocol) standardizes communication between code editors/IDEs and AI coding agents - the LSP (Language Server Protocol) equivalent for the agentic era. Agents implementing ACP work with any compatible editor and vice versa, with SDKs available in Python, TypeScript, Rust, and Kotlin.
- Agent Skills are emerging as structured capability packages that extend agents with complete domain knowledge, decision logic, and micro-workflows - moving beyond simple tool calls to composable, reusable expertise modules.
The same principles that make human teams effective - specialization, clear responsibilities, standard communication protocols, quality reviews - apply directly to agent teams. The difference is that the infrastructure to support these principles at scale is finally catching up to the ambition.
The best way to learn multi-agent architecture is to build one, break it, and build it again. Start small, ship something real, and let production teach you what the diagrams never will.
Recommended Reading
- Unleashing the Power of Collaborative AIs - how I run 11 specialist agents on my homelab and what I have learned about collective AI intelligence
- MCP Explained from Inside Out - deep dive into the Model Context Protocol that standardizes how agents connect to tools
- The Three Layers of AI Transformation - why 94% of enterprise AI pilots fail and where to start instead
Share :
You May Also Like
What Can We Do With Self-Hosted ChatGPT
The Journey Begins A few weeks ago, I managed to install a self-hosted version of ChatGPT on my homelab - the LLaMA model, open-sourced by Meta. I started with Alpaca-6B. The speed was acceptable, but …
Read More
Tech Debt: From a Technical Jargon to Real-World Impacts
What Started This I recently gave a presentation at my company about tech debt - sharing knowledge, techniques, and experiences on how to manage it properly and efficiently. The response convinced me …
Read More