July 7, 2025
Table of Contents
I had a Kubernetes cluster running inside my NAS. ArgoCD managing deployments. Cloudflare Zero Trust handling ingress. On paper, it was an enterprise-grade homelab. In practice, it was an enterprise-grade headache. The control plane alone burned ~45W at idle, every upgrade required careful coordination across three layers, and all my traffic was routing through a third-party network. Something had to give.
So I gut-renovated the entire setup. Not a cosmetic tweak - a ground-up rearchitecture driven by first-principles thinking and the ruthless elimination of anything that did not move the needle.
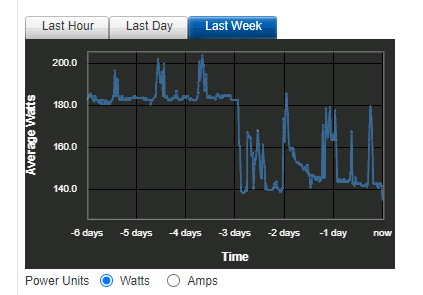
| Metric | Before | After |
|---|---|---|
| Power draw (idle) | ~180W | ~140W (-22%) |
| Recovery Time Objective | Hours (manual) | < 1 hour (automated) |
| IaC coverage | Apps only (ArgoCD) | Apps + infra + networking + DNS |
| Data path | Routed through Cloudflare | Fully self-hosted edge |
| Stack complexity | K8s + ArgoCD + Cloudflare | Docker + Terraform + Traefik |
The takeaway that applies beyond homelabs: in almost two decades of scaling enterprise platforms, I have learned that elite teams scale value, not vanity metrics. If an architecture cannot grow gracefully, respond quickly, and justify its own cost, no amount of tooling will save it. But what exactly was wrong with the old setup?
What Was the Old Architecture Costing Me?
My previous stack was built with enterprise-grade tools - powerful, but wildly overbuilt for a homelab. Classic sledgehammer-meets-nut.
| Component | What It Did Well | The Hidden Cost |
|---|---|---|
| Kubernetes Cluster (inside NAS) | Phenomenal for distributed systems at scale | Control plane, networking, operators demanded constant CPU/RAM - ~45W at idle |
| ArgoCD for GitOps | Ensured cluster state matched Git beautifully | Another resource-hungry layer on top of an already heavy K8s foundation |
| Cloudflare Zero Trust | Simplified ingress, no exposed ports | All traffic routed through third-party - data privacy trade-off |
Elegant on paper, this setup was a poster child for diminishing returns. ArgoCD piled on another container stack, and every third-party dependency introduced a new blast radius. A study from Datadog shows the average Kubernetes cluster runs significant overhead from system components alone - overhead that makes sense at scale but is pure waste for a homelab.
flowchart
subgraph Internet
Domain["*.domain.ext"] --> CFZT["Cloudflare Zero Trust"]
end
subgraph Homelab
subgraph Dell["Dell R520"]
iDRAC["iDRAC"]
subgraph Proxmox["Virtualization Host"]
subgraph NAS["NAS VM"]
RAID1["RAID1 Array"]
subgraph K8s["Kubernetes Cluster"]
CFT["Cloudflare Tunnel"]
ArgoCD["ArgoCD"]
Vault["Vault"]
GenAI["GenAI"]
Others["Apps..."]
Kopia["Backup"]
CFT --> ArgoCD & Vault & GenAI & Others & Kopia
end
ArgoCD & Vault & GenAI & Others & Kopia --> RAID1
end
end
end
Router --> Dell & iDRAC & Proxmox
end
Proxmox & NAS --> NewRelic((NewRelic))
CFZT <-.-> CFT
Users --> Domain
What Does “Just Enough” Look Like?
Each component in the new architecture was chosen to perform its function efficiently - nothing more.
How Did Dropping K8s Change Everything?
The biggest single change. Applications now run as vanilla Docker containers inside a separate VM, managed by Terraform. This move alone delivered the majority of power savings - the system’s idle draw dropped dramatically without K8s overhead. No control plane, no etcd, no kubelet - just containers running directly under Docker’s supervision.
Why Terraform Cloud Instead of ArgoCD?
With K8s gone, a K8s-native tool like ArgoCD no longer fit. I migrated to Terraform Cloud - a strategic shift towards holistic IaC. Terraform defines not just applications, but the entire environment: Proxmox VMs, network configurations, DNS records - all in one place. The blast radius of any change is visible in the plan before it executes.
How Did I Reclaim the Edge?
To replace Cloudflare Zero Trust, I deployed a self-hosted edge stack:
| Component | Role | Why It Fits |
|---|---|---|
| Traefik Reverse Proxy | Routes traffic, auto-discovers containerized services | Lightweight, zero-config for Docker containers |
| Let’s Encrypt | Automatic SSL/TLS certificates | Built into Traefik via ACME - no manual cert management |
| Google SSO | Multi-factor authentication | Robust security without third-party tunnels, full data path control |
The result: all traffic stays within my network unless it explicitly needs to leave. No third-party tunnel, no routing through external CDNs for local services.
flowchart
subgraph Homelab
subgraph Dell["Dell R520"]
iDRAC["iDRAC"]
subgraph Proxmox["Virtualization Host"]
direction LR
Terraform["Terraform"] --> NAS & Docker
subgraph NAS["NAS VM"]
RAID1["RAID1 Array"]
end
subgraph Docker["Docker VM"]
Traefik["Reverse Proxy"]
Vault["Vault"]
GenAI["GenAI"]
Others["Apps..."]
Kopia["Backup"]
Traefik --> Vault & GenAI & Others & Kopia
end
Vault & GenAI & Others & Kopia --> RAID1
end
end
end
Proxmox & NAS & Docker --> Grafana((Grafana Cloud))
Users --> Domain["*.domain.ext"] --> Router --> iDRAC & Traefik
Traefik <-.-> Google((Google SSO))
Key Takeaways
- Challenge your assumptions. Popular does not equal appropriate. Start with the problem statement, not the tool catalogue.
- Model Total Cost of Ownership. Energy, licenses, cognitive load, incident response - they all end up on your P&L one way or another.
- Optimise for MTTR (Mean Time To Recovery) over Peak Throughput. Most real-world downtime cost sits in recovery, not capacity ceilings.
- Automate the boring, not the rare. Automation debt is real - script only what you touch frequently.
- Default to simplicity. Fewer moving parts means a tighter security posture and happier on-call rotations.
- Instrument relentlessly. What gets measured gets improved - and funded.
Pick one component in your infrastructure that you suspect is overengineered for its actual workload. Measure its resource consumption for a week. Then ask: “What is the simplest thing that could replace this and still meet the requirements?” The answer might save you more than you expect.
Share :
You May Also Like
Fun Things To Do With Self-Hosted Generative AI
Weekends are my time to break things and build things. My homelab runs a full generative AI stack - models, workflows, UIs - and I use that freedom to experiment with stuff that commercial services …
Read More
The Modern Leader
There’s a pattern I’ve seen play out more than once. A team ships a big release, leadership celebrates, and within weeks the strongest engineers start disengaging. They become quieter in …
Read More